
Translator pen accuracy and translation quality in real use
Translator pen accuracy depends on OCR recognition, language pair compatibility, translation engine quality, and real use conditions such as scan stability and printed text clarity. These factors influence how correctly source text is captured and converted into a translation result. In most cases, accuracy varies across environments rather than staying constant.
Translator pen accuracy can be separated into scanning accuracy and translation quality, where OCR recognition affects how well printed text is captured, while the translation engine shapes the meaning transfer. Dictionary support and language pairs also influence how consistent results appear across different scripts. For broader device context and usage considerations, see the translator pen guide.
In real use, clear printed text, supported language pairs, offline mode limitations, dictionary support, and text-to-speech output can each change perceived translation quality. These conditions often interact, especially when scan conditions or text clarity vary. This makes everyday scanning accuracy dependent on both input quality and system capability.
How accurate translator pens are for everyday scanning
Translator pen accuracy for everyday scanning is generally reliable with clear printed text, but it depends on OCR recognition quality, language pair support, text type, and scan condition. In real use, the accuracy outcome changes based on how stable the scan is and how the device processes structured printed input.

Translator pen accuracy in everyday scanning is best understood by separating OCR recognition from translation quality, since each affects a different stage of the result. OCR recognition focuses on capturing printed text correctly, while translation quality determines how that captured content is converted into meaning. This distinction is important because accuracy is not a single measurement across scanning, translation output, offline mode, and speech output.
| OCR recognition | Translation quality |
|---|---|
| Captures printed text based on scan condition and text clarity | Converts captured text based on language pair and translation engine |
In everyday scanning situations such as menus, textbooks, labels, and short printed phrases, translator pen accuracy varies depending on language pair compatibility and text type clarity. Clear printed text usually improves scan result consistency, while complex layouts or mixed languages can reduce accuracy outcome stability. This creates a conditional performance range based on real use conditions rather than a single fixed level.
Why accuracy claims need real-use context
Accuracy claims for translator pens require real-use context because scan conditions and language tasks change how performance is interpreted. Claim wording often acts as the first screening signal for whether an expectation is realistic.

Why accuracy claims need real-use context becomes clearer when comparing clean printed text with complex phrases or idioms. Clean print usually produces more stable scan results, while complex expressions can change the accuracy outcome depending on language pair and text structure. This difference shows why claims must be read with qualification rather than assumption.
Why accuracy claims need real-use context can be evaluated through the following decision signals that qualify marketing statements by usage condition:
- Claim wording vs scan condition
- Supported languages vs language task
- Text complexity vs accuracy outcome
- Offline availability vs output quality
- User handling vs decision signal
Where scanning accuracy and translation accuracy differ
Scanning accuracy refers to how well OCR input captures source text into recognized characters from the source text, while translation accuracy refers to how well meaning is preserved in the target language through grammar handling and dictionary handling. Both evaluate different stages, separating recognition of source text from interpretation of target meaning.
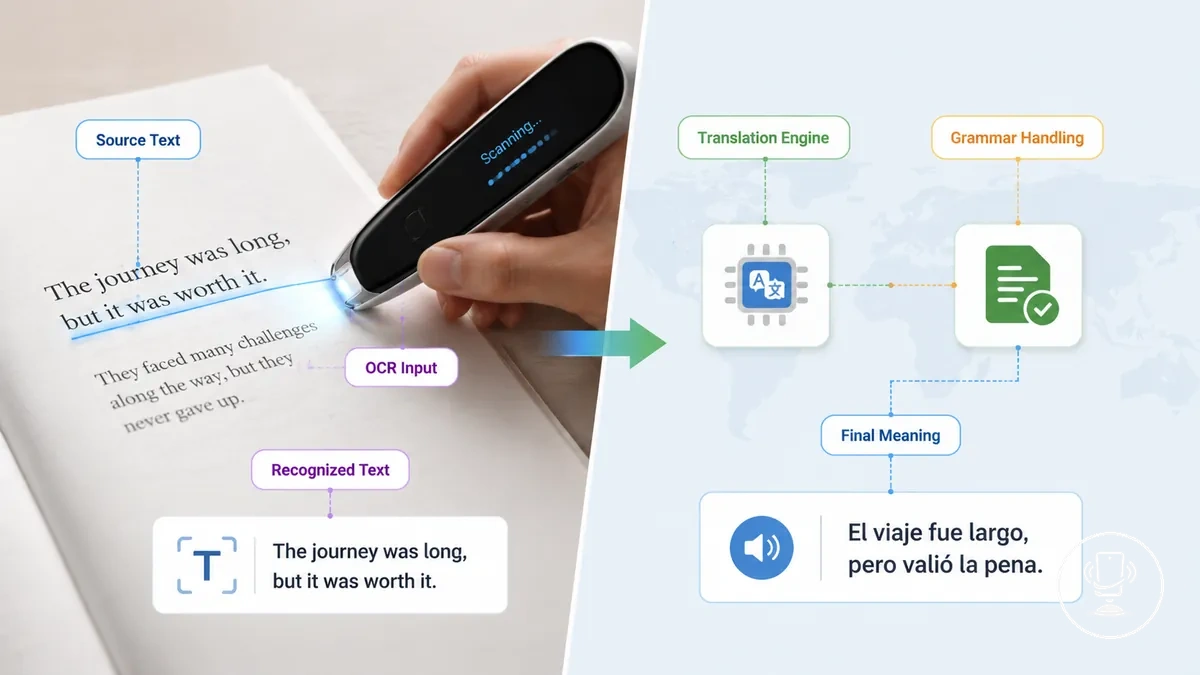
Where scanning accuracy and translation accuracy differ becomes clear when OCR input correctly captures text but meaning shifts during language processing. In such cases, recognized characters may be accurate while grammar handling still changes the result in the target language. This separation is often described in OCR scan translation workflows.
| Accuracy type | What it evaluates |
|---|---|
| OCR input | Captures source text into recognized characters |
| Recognized characters | Checks accuracy of scanned source text representation |
| Grammar handling | Evaluates how target language structure is formed |
| Phrase meaning | Assesses dictionary handling and phrase meaning interpretation |
| Final meaning | Measures overall translated meaning in target language |
A clean scan can still produce weak translation when dictionary handling and grammar handling do not fully preserve meaning in the target language, even if OCR input is correct and recognized characters are accurate.
OCR conditions that improve or reduce accuracy
OCR accuracy in translator pens depends on OCR conditions that control how clearly source text is captured into recognizable characters. Printed text clarity, font shape, line spacing, page surface, lighting, scan speed, and scanner alignment are the main conditions that affect recognition of source text. These factors together determine how reliably OCR input is produced.
OCR conditions that improve or reduce accuracy become more visible when comparing different scan environments and text layouts.

In practice, lighting angle, uneven page surfaces, or fast scan speed can reduce recognition stability even when printed text is readable. Strong OCR input is important because weak capture at this stage can reduce the quality of later translation output, especially when grammar handling and dictionary handling depend on accurate source text.
OCR conditions table
| OCR condition | Better value or condition | Risk when poor | Accuracy effect |
|---|---|---|---|
| Printed text clarity | Sharp, high contrast text | Blurred or faded characters | Improves recognition accuracy |
| Font shape | Simple, standard fonts | Decorative or complex fonts | Affects character recognition stability |
| Line spacing | Clear separation between lines | Crowded or overlapping lines | Reduces character isolation accuracy |
| Page surface | Flat, smooth surface | Curved or textured pages | Impacts scan consistency |
| Lighting | Even, glare-free light | Shadows or strong reflections | Reduces OCR input clarity |
| Scan speed | Steady, controlled movement | Fast or uneven movement | Disrupts character capture |
| Scanner alignment | Straight alignment with text | Angled or unstable positioning | Reduces recognition accuracy |
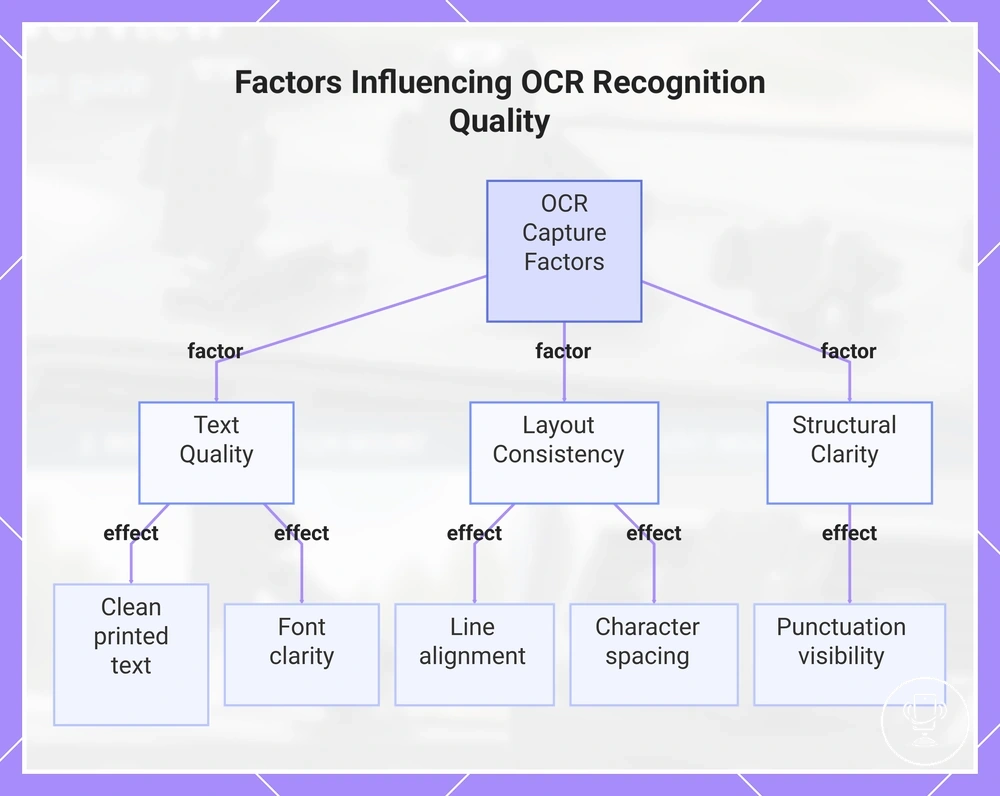
Clean printed text, font clarity, and line alignment
Clean printed text improves OCR capture because it provides clear source text boundaries for recognition. Font clarity and line alignment directly support how accurately the translator pen identifies characters, while paper contrast, character spacing, and punctuation visibility further influence OCR conditions that affect recognition of source text.
OCR capture becomes more stable when text is structured in a straight and predictable format, such as evenly aligned lines and readable fonts. A standard textbook line usually produces more consistent recognition compared to stylized packaging text with compressed spacing or decorative lettering. These differences show how clean printed text and line alignment influence input recognition quality.
- Clean printed text: improves OCR capture by reducing character ambiguity
- Font clarity: supports stable recognition of individual characters
- Line alignment: helps maintain consistent scan tracking across text rows
- Character spacing: reduces merging or splitting of OCR inputs
- Punctuation visibility: improves recognition of sentence structure markers
This chart shows the main factors that affect OCR capture quality from printed text, grouped by text quality, layout consistency, and structural clarity.
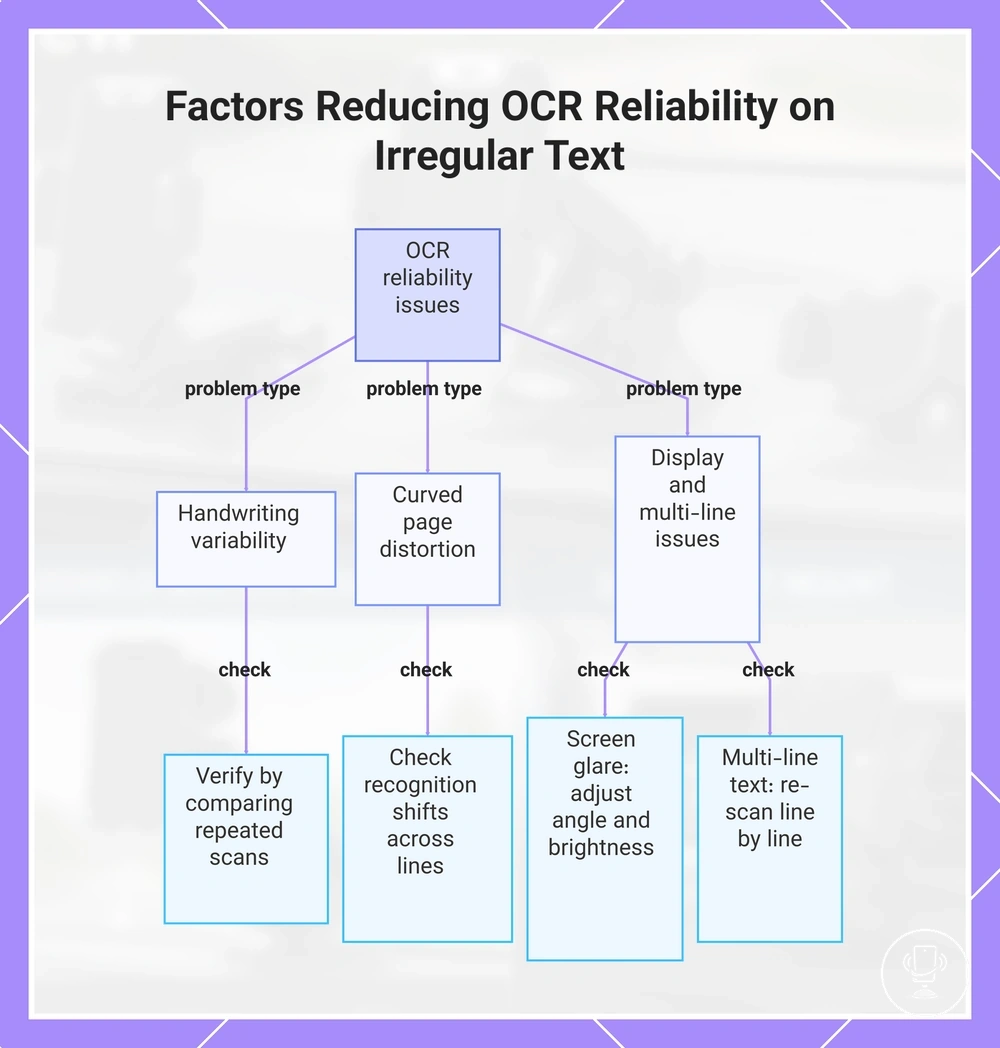
Handwriting, curved pages, screens, multi-line text
OCR reliability is reduced when handwriting, curved pages, screens, and multi-line text introduce irregular input conditions that disrupt source text recognition. These irregular text surfaces affect line tracking and increase scanning errors in OCR capture, depending on device and input quality. Common problem types include handwriting variability, page curvature, screen glare, and multi-line text breaks.
Even with these limitations, some outputs may still be usable depending on model and scan conditions. Re-scanning or manual checking can improve results when line tracking stabilizes and screen glare or page curve is reduced.
Limitations checklist
- Handwriting variability: uneven strokes can reduce OCR reliability; verify by comparing repeated scans
- Curved pages: page curvature can distort line tracking; check for recognition shifts across lines
- Screen glare: reflections may interfere with OCR capture; adjust angle to confirm readability changes
- Multi-line text: broken line tracking may occur; verify by re-scanning line by line
- Screens: display rendering differences can affect scanning accuracy; test under different brightness levels
This chart shows the main problem types that reduce OCR reliability on irregular text surfaces and the recommended verification checks for each.
Translation quality factors after the text is recognized
Translation quality after OCR capture depends on language pair, sentence context, idioms, grammar handling, dictionary depth, and domain vocabulary. Recognized text still requires meaning processing to form accurate translation quality, and OCR dependency only affects the input layer.
Idioms, sentence context, and domain vocabulary change how output meaning is formed in different languages. Short phrases may translate differently when grammar handling or phrase recognition varies. Language pair distance can also affect interpretation consistency. The following table organizes key post-OCR translation factors for evaluation.
Recognized text does not guarantee correct translation quality because meaning depends on language structure, not only word capture. Word-level accuracy can still produce awkward or incomplete output when context is weak. This creates a clear separation between recognition and final meaning interpretation.
| Translation factor | What changes | Accuracy risk | Evaluation cue |
|---|---|---|---|
| Language pair | Structural conversion between languages | Meaning shifts or simplification | Check cross-language consistency |
| Sentence context | How words connect in a full sentence | Fragmented or unclear meaning | Review sentence-level coherence |
| Idioms | Cultural phrase interpretation | Literal or incorrect meaning | Compare intended vs literal output |
| Grammar handling | Sentence structure formation | Awkward or incorrect structure | Check syntax alignment |
| Dictionary depth | Word meaning coverage | Incomplete or basic translation | Verify term accuracy |
| Domain vocabulary | Specialized term interpretation | Incorrect technical meaning | Confirm field-specific terms |
| Phrase recognition | Multi-word meaning handling | Broken or literal phrase output | Check phrase-level meaning |
Language pair support and sentence context
Language pair and sentence context determine usable translation quality because compatibility depends on the relationship between source language and target language and how meaning is structured across sentences. Translation quality varies when grammar distance increases or when sentence context is too limited for stable interpretation.
Usable translation depends on sentence length, grammar distance, and context dependence across different language pairs. Short sentences may translate more consistently, while longer or structurally complex inputs can increase variation in meaning. Offline availability can also influence how language resources are applied during processing.
Supported language coverage does not guarantee equal output quality across all pairs, since language direction and sentence structure can change interpretation results. For broader reference, see language support.
Dictionary depth, phrase handling, and grammar limits
Dictionary depth and phrase handling define how internal vocabulary systems influence translation quality, especially when converting source language input into usable target language output. Dictionary entries, idioms, technical terms, inflection patterns, and sentence structure interact with grammar limits to shape how meaning is assembled, while phrase-level context determines how multi-word expressions are interpreted.
In practice, dictionary entries can support literal translation of individual words, but phrase handling becomes more important when idioms or multi-word expressions depend on contextual meaning. Technical terms and inflection can also vary in output when grammar limits restrict how sentence structure is processed. This difference is most visible when literal translation produces less usable meaning than phrase-level context handling.
Example: A phrase like “kick the bucket” translated word-by-word may lose its intended meaning, while phrase handling preserves the contextual idea of death rather than physical action.
- Dictionary depth: affects vocabulary depth and technical term coverage
- Phrase handling: determines idioms and phrase-level context interpretation
- Grammar limits: influence sentence structure and inflection processing
Online and offline accuracy trade-offs
Online accuracy and offline accuracy differ as a conditional trade-off between connectivity, language packs, and translation depth. Online mode depends on Wi-Fi access and broader language resources, while offline mode relies on offline language packs that define available translation scope when no network is available.
In travel conditions or low-connectivity environments, offline mode becomes more relevant because reliability depends less on network stability and more on preinstalled language packs. These conditions shape performance when speed and continuity matter more than expanded vocabulary coverage.
Online mode can extend dictionary scope through connected language resources and update frequency, which may improve translation depth for newer or more complex content. However, this advantage depends on consistent connectivity and stable Wi-Fi access during use.
Choice between modes depends on whether the priority is offline reliability in variable travel conditions or broader translation depth supported by online resources. The trade-off is also influenced by language pack coverage and usage context, and can be further explored through offline translation limits.
| Mode | Strength | Limitation | Best-fit use case |
|---|---|---|---|
| Online mode | Expanded translation depth via connected language resources | Requires Wi-Fi access and stable connectivity | Complex translation tasks with internet access |
| Offline mode | Works without connectivity using offline language packs | Limited dictionary scope compared to online resources | Travel and low-connectivity environments |
When offline translation is accurate enough
Offline translation is accurate enough when the task involves simple printed text and common vocabulary supported by installed language packs. It depends on how well offline language packs cover the required language pair and how stable the vocabulary set is for basic meaning transfer.
In travel phrases, classroom reading, or low-connectivity use, offline translation can provide practical understanding without requiring network access. It is often used when speed and basic comprehension matter more than full translation depth, especially in environments where connectivity is limited and only basic understanding is required.
Offline accuracy checklist
The following checklist helps identify when offline translation is likely sufficient for practical use:
- Simple printed text with clear structure
- Common vocabulary supported by offline language packs
- Travel phrases used for basic communication
- Classroom reading for general understanding
- Low-connectivity use where Wi-Fi access is unavailable
- Tasks focused on basic meaning rather than detailed translation depth
When online translation gives better results
Online translation gives better results when longer sentences, less common phrases, updated language resources, broader vocabulary, and context-sensitive translation are required. It depends on connected systems that expand language coverage beyond offline limits while still relying on correct OCR input quality for initial text recognition.
In practice, online translation may improve meaning clarity for complex inputs, but it remains dependent on OCR input quality before translation begins. If scan accuracy is weak, even improved online resources cannot fully correct recognition errors, which can affect final output consistency and interpretation.
The following points describe where online translation can improve output quality compared with offline mode:
- Longer sentences with more complex structure handling
- Less common phrases supported by updated language resources
- Broader vocabulary coverage through connected translation systems
- Context-sensitive translation for improved meaning flow
- Improved adaptation to evolving language usage patterns
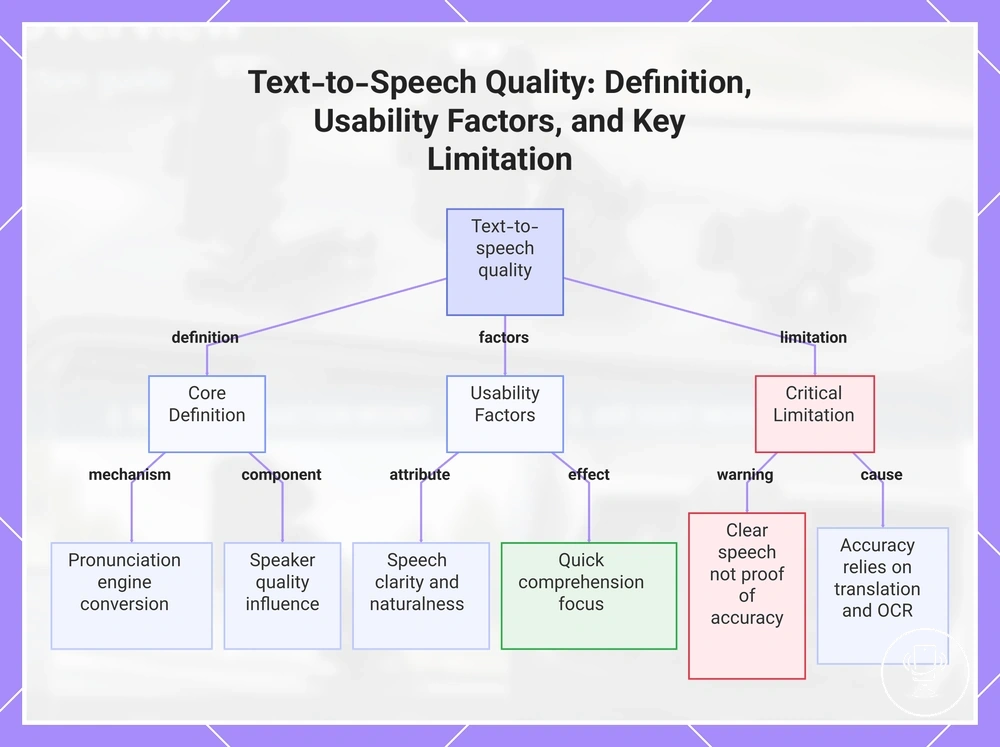
Text-to-speech quality and pronunciation reliability
Text-to-speech quality refers to how written output is converted into spoken language through a pronunciation engine, and how speaker quality influences the resulting speech output. It affects how clearly translated written output is heard and how reliably pronunciation reliability reflects the intended text. This creates a usability layer where pronunciation reliability depends on supported languages, volume control, and system configuration.
In learner, travel, and reading-support contexts, text-to-speech quality affects how easily written output becomes understandable spoken translation. Voice clarity, pacing, and accent naturalness influence whether speech output feels usable for quick comprehension rather than detailed review. These factors depend on speaker quality and pronunciation engine behavior across supported languages.
Clear speech output does not prove that the written output is semantically accurate. Text-to-speech quality improves perceived usefulness, but meaning accuracy still depends on the underlying translation system and OCR input quality before spoken conversion. This separation defines the boundary between pronunciation reliability and semantic translation accuracy.
- Pronunciation consistency across supported languages
- Voice clarity affecting speech output usefulness
- Speed and pacing control during spoken translation
- Accent naturalness depending on pronunciation engine
- Volume balance for different usage contexts
This chart shows the definition, usability factors, and critical limitation of text-to-speech quality, clarifying how pronunciation reliability differs from semantic accuracy.
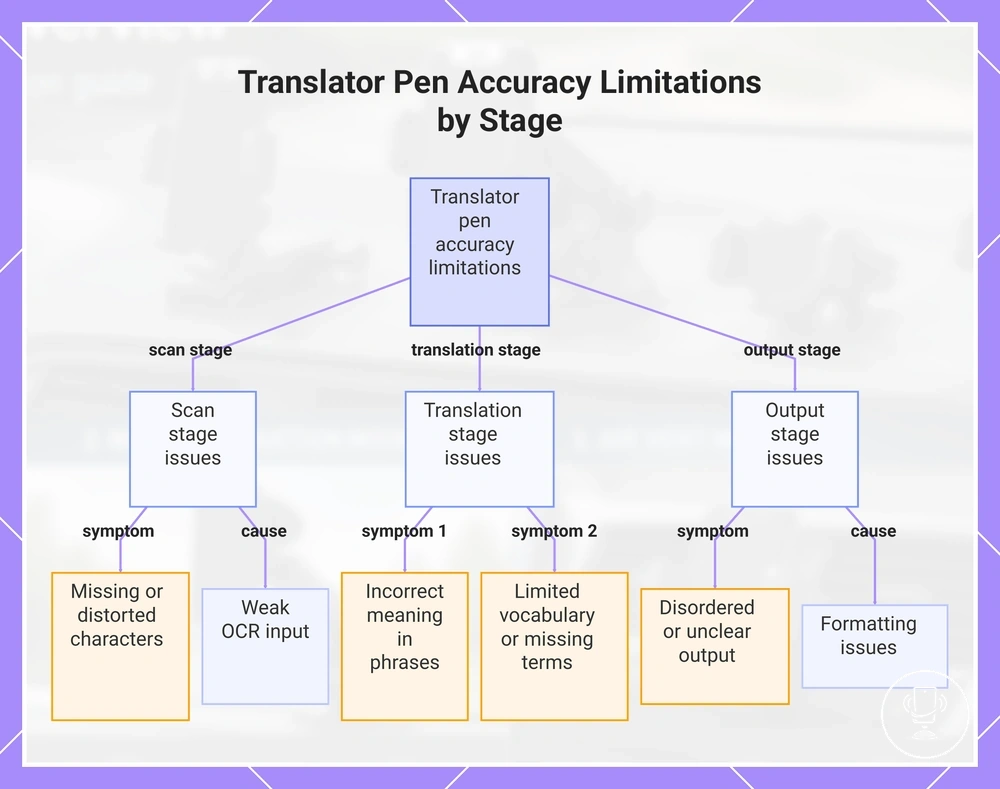
Common translator pen accuracy limitations
Accuracy limitations in translator pen usage depend on input quality, language coverage, operating mode, and user handling in practical use. These accuracy limitations often appear when weak OCR input, difficult text types, or unsupported languages interact with formatting or offline limits. As a result, output quality can vary depending on whether the issue originates from scanning, translation processing, or final speech/text output.
Difficult text types, weak OCR input, unsupported languages, offline limits, idioms, formatting issues, and correction needs can each contribute to translation issues in different ways. Weak OCR input often produces scan problems that reduce recognition quality. Unsupported languages or offline limits may reduce language pair coverage. Idioms and formatting can affect meaning structure and output quality, requiring diagnostic separation to identify the source of the issue.
To troubleshoot accuracy limitations effectively, it is important to determine whether the issue is caused by scanning, translation processing, or output quality. This separation helps narrow down the cause of reliability limits before applying any correction steps. The checklist below provides structured symptom-based diagnosis.
Accuracy limitations can be identified through symptom-to-cause mapping across scan, translation, and output stages.
- Symptom: Missing or distorted characters → Likely cause: weak OCR input → What to check: scan alignment and text clarity → Likely outcome: reduced recognition accuracy
- Symptom: Incorrect meaning in phrases → Likely cause: idioms or translation mismatch → What to check: language pair and phrase context → Likely outcome: altered or literal output meaning
- Symptom: Limited vocabulary or missing terms → Likely cause: unsupported languages or offline limits → What to check: language mode and availability → Likely outcome: simplified translation output
- Symptom: Disordered or unclear output → Likely cause: formatting issues → What to check: source text structure → Likely outcome: reduced output quality and readability
This chart maps common accuracy limitations of translator pens to the scanning, translation, and output stages, showing key symptoms and causes.
Content types translator pens handle reliably
Content types translator pens handle reliably depend on clear, printed, short, and context-light text, where accuracy is usually stronger under suitable model quality and language pair conditions. These content types reduce interpretation complexity and support more consistent recognition and translation in everyday use cases. Reliability remains conditional and varies with input clarity and system support.
In everyday reading, travel, and study contexts, these content types often align with expected translation performance. Short and structured everyday text can improve consistency, but results still depend on model quality, language pair compatibility, and print clarity in practical use situations.
Common content types that can support stronger accuracy potential include:
- Textbooks: structured content often used in study contexts with clearer sentence organization
- Menus: short everyday text used in travel scenarios with simple vocabulary patterns
- Labels: compact printed material with limited context for direct recognition
- Printed worksheets: structured educational tasks with consistent formatting
- Short instructions: brief procedural text with reduced linguistic complexity
- Simple vocabulary lists: basic everyday terms with lower translation ambiguity
Content types that often need checking or correction
When complex or sensitive text is scanned or translated, checking is often required because correction risk increases with handwriting, stylized fonts, legal wording, medical wording, idioms, dense technical text, curved pages, and screen glare :contentReference[oaicite:0]{index=0}. These content types tend to increase correction needs due to weak OCR input, formatting variation, or translation ambiguity, where checking becomes a realistic verification step rather than an exception.
In situations involving important decisions, additional verification is often required because even small interpretation differences can affect understanding. This applies when users rely on translated output for clarity in sensitive contexts. A stop-signal approach is appropriate in such cases: pause and verify before using the result for critical decisions, especially when meaning is unclear or incomplete.
Content types that often require checking or correction include:
- Handwriting: requires checking due to variable stroke recognition and higher correction risk
- Stylized fonts: may increase correction needs because formatting can affect character recognition
- Legal wording: needs verification due to precision requirements in meaning
- Medical wording: requires checking because dense terminology can vary by language pair
- Idioms: often need correction due to context-dependent meaning shifts
- Dense technical text: may require review because structure and terminology increase correction risk
- Curved pages: can affect scanning accuracy and require checking for distortion
- Screen glare: may reduce clarity and increase the need for verification during OCR capture
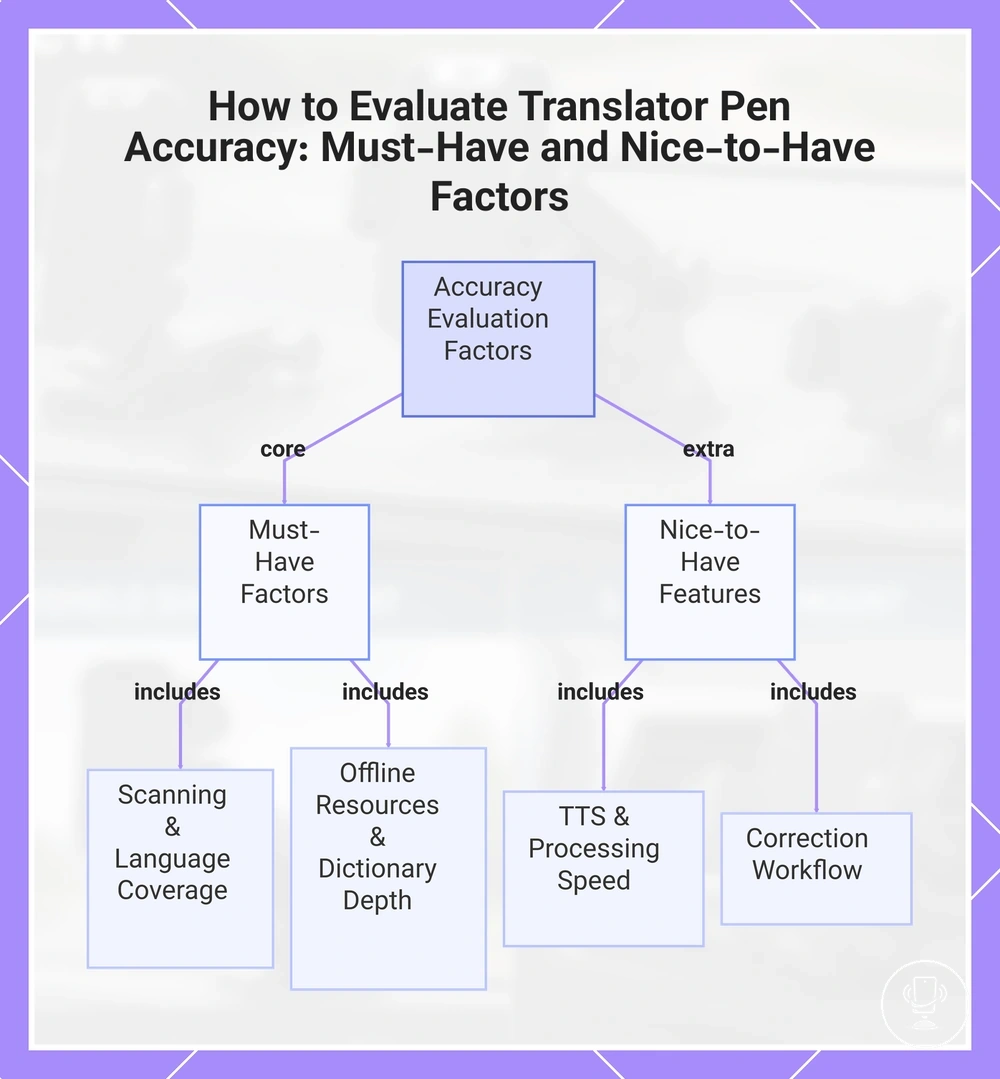
How to evaluate accuracy before choosing a translator pen
Accuracy evaluation before choosing a translator pen depends on use case, language pair, OCR conditions, and available review evidence. These factors determine how reliably input text is recognized and translated in real conditions. The decision should focus on how these elements interact rather than isolated feature claims.
Must-have accuracy factors usually include scanning reliability, supported languages, offline resources, and dictionary depth. Scanning reliability affects how well OCR conditions handle printed or imperfect text. Supported languages and offline resources define the usable range in different environments. Dictionary depth influences how well meaning is preserved in translation, especially across different language pair structures. These elements form the baseline checklist setup for evaluation.
Nice-to-have factors include text-to-speech output, processing speed, and correction workflow support. Text-to-speech can help validate pronunciation clarity but does not define core translation accuracy. Speed influences usability in real-time scenarios, while correction workflow affects how users refine or review outputs. These factors should be compared only after must-have conditions are met.
Selection should focus on matching accuracy requirements to real usage conditions rather than assuming uniform performance across all contexts. Review evidence patterns, use case needs, and language pair behavior should guide the final decision. This approach helps separate essential accuracy requirements from secondary feature improvements before applying structured evaluation.
Here are product examples that may make comparison easier. Before buying, always review the compatibility criteria, essential features, and product details.





Decision checklist for evaluating accuracy should be used to organize accuracy factors before choosing a translator pen. Accuracy evaluation should be judged by use case, language pair, OCR conditions, and review evidence before comparing options.
- Scanning reliability: evaluates OCR conditions because inconsistent recognition reduces translation stability; decision signal: prioritize if working with varied or low-quality print
- Supported languages: defines usable language pair coverage because limited support restricts translation scope; decision signal: required if multilingual use is expected
- Offline resources: affect performance without connectivity because missing offline support limits usability; decision signal: important for travel or low-network environments
- Dictionary depth: influences meaning accuracy because shallow coverage reduces translation detail; decision signal: necessary for complex or technical text
- Text-to-speech: supports output verification because spoken review helps confirm results; decision signal: optional unless audio review is needed
- Correction workflow: improves review and adjustment because structured correction reduces errors; decision signal: useful when iterative checking is required
This chart organizes the key accuracy factors and nice-to-have features to check before choosing a translator pen, based on use case, language pair, and OCR conditions.
Accuracy signals in specifications and product descriptions
Specifications and product descriptions provide accuracy signals rather than proof when evaluating translator pen performance, as these spec claims mainly indicate potential behavior under different OCR conditions and language coverage patterns :contentReference[oaicite:0]{index=0}. They function as screening signals that help interpret feature scope, but they still require real-use confirmation to understand actual translation performance across contexts.
Vague accuracy percentages in product descriptions require careful interpretation because they often lack testing method details, dataset context, or clear usage conditions. Without this context, such claims may not reflect real scanning reliability or translation behavior. Real-use confirmation is needed to validate whether these stated outcomes match practical performance under typical language pair and OCR conditions.
Specifications as accuracy signals should be evaluated using a structured screening approach before making selection decisions.
- OCR language support: indicates possible recognition scope because it defines supported scripts; decision signal: check alignment with intended language pair
- Offline language packs: indicate usable offline capability because they define available translation resources; decision signal: required for non-network usage
- Dictionary claims: suggest vocabulary coverage because they reflect term depth; decision signal: important for technical or dense text
- Pronunciation features: indicate output support because they help with spoken verification; decision signal: optional for audio-based review
- Scan resolution / camera quality: suggest input clarity because better capture can improve OCR conditions; decision signal: important for low-quality text sources
- Update support: indicates long-term improvement potential because updates may expand language handling; decision signal: relevant for evolving language needs
Review patterns that reveal real-world reliability
Review patterns that repeat across many users are more useful than isolated comments when judging real-world reliability. They highlight consistent behavior in scanning success and correction frequency across similar usage conditions rather than one-off experiences.
Scanning success reports, language-pair complaints, offline mode issues, text-to-speech clarity feedback, correction frequency mentions, and use-case fit comments often appear in clustered user feedback. When these signals repeat across multiple contexts, they can indicate stable or unstable performance patterns. Single mentions alone are not sufficient to interpret reliability, which is why pattern grouping matters. This sets up the evidence checklist below.
Reviews support evaluation but do not replace criteria-based assessment of real-world reliability. They should be interpreted as supporting signals alongside language pair conditions and scanning constraints rather than final proof of performance. More structured patterns can be explored through real-world translator pen reviews for deeper comparison of repeated signals.
Evidence checklist for real-world reliability patterns should focus on repeated signals rather than isolated opinions.
- Scanning success patterns: repeated success or failure reports may indicate OCR stability under real conditions
- Language-pair complaints: recurring issues may suggest limitations in translation coverage between specific languages
- Offline mode issues: repeated mentions may indicate constraints in non-connected environments
- Text-to-speech clarity: consistent feedback may reflect usability of spoken output
- Correction frequency: repeated correction needs may signal OCR or translation inconsistency
- Use-case fit: recurring usage mismatches may indicate limited suitability for certain scenarios
- Repeated accuracy patterns: clustered feedback trends may suggest overall reliability behavior across users